¶ XJTU-ICS LAB 3: Attack Lab
¶ 实验简介
本实验将通过分析和攻击两个包含不同安全漏洞的程序(ctarget和rtarget)来增进你对程序安全性的理解。通过本实验,你将可以:
- 理解缓冲区溢出漏洞及其对程序安全性的影响,以及黑客如何利用这类漏洞执行恶意操作。
- 学习如何通过合理的编程和利用编译器以及操作系统提供的安全机制,增强自己编写的程序的安全性。
- 深入了解函数调用过程中的栈管理机制以及参数在函数之间传递的方式。
- 学会使用
gcc工具生成用于漏洞攻击的字节序列,了解x86-64架构下的指令编码方法。 - 提升对
objdump、gdb等工具的熟练度,这些工具对于程序分析和调试至关重要。
Note:
- 请注意,本实验的目的是为了学习,通过模拟攻击来增进对安全漏洞的理解和防范意识。本实验内容应仅用于学习目的,严禁用于任何非法或不道德的活动。
- 本实验开始前,需要学习CS:APP3e第3.10.3节和第3.10.4节的知识。
¶ 注意事项
-
每个学生的题目都是独立且随机的,请遵循学术诚信原则,不要抄袭或参与任何不诚实的行为。
-
请你在
ICSServer上完成本次实验。 -
你需要将解题的答案写在
phase1~5.txt5个文件中,可以通过autograder.py计算自己的得分。 -
你在进行
attack实验时不可以使用攻击跳过程序中的一些有效代码。具体来说,你在攻击时使用的字符串中嵌入的用于ret指令跳转的地址都应指向以下三个地址之一:-
函数
touch1、touch2或touch3的地址。 -
你自己注入的代码的地址。
-
gadget farm中某个gadget的地址。
-
-
你只能从文件
rtarget中的函数start_farm和end_farm之间的地址去构造你的gadget。
第一次阅读本文档时,可能觉着这些注意事项有些摸不着头脑,后续还会有对这些规则的详细说明。
¶ 实验前置知识
这个小节仅对CS:APP3e第3.10.3节简单介绍一下,并不全面,如果对缓冲区溢出的知识比较熟悉可以略过此节。如果想了解更多请自学课本3.10.3节中的内容。
C语言对于数组引用并不进行任何边界检查,而且局部变量和状态信息都存放在栈中。这两种情况结合到一起就会导致严重的程序错误,对越界的数组元素的写操作会破坏存储在栈中的状态信息。当程序使用这个被破坏的状态,试图重新加载寄存器或执行ret指令时,就会出现很严重的错误。
例如缓冲区溢出(buffer overflow),如果程序在栈中分配某个字符数组来保存一个字符串,但是字符串的长度超出了为数组分配的空间。
例如有一个echo函数的代码如下:
/* Read input line and write it back */
void echo() {
char buf[8];
gets(buf);
puts(buf);
}
在调用echo函数时,我们可以通过程序的汇编语言得知栈的组织基本如下图所示:

图中echo程序在栈中为自己分配了24字节的地址空间(echo的栈帧),字符数组buf位于栈顶,可以看到,buf之外echo还分配了16字节是未被使用的。此时只要用户输入不超过7个字符,gets返回的字符串就可以放进buf的空间中,不过,长一些的字符串就会导致gets覆盖栈上存储的某些信息,随着字符串变长,下面的信息就会被破坏。
| 输入的字符数量 | 附加的被破坏的状态 |
|---|---|
0~7 |
无 |
9~23 |
未被使用的栈空间 |
24~31 |
返回地址 |
32+ |
caller中保存的状态 |
字符串在23个字符以前都没有特别严重的后果,但是超过23个字符会导致返回指针的值,以及更多的保存状态被破坏。
如果存储的返回地址的值被破坏了,那么ret指令会导致程序跳转到一个完全意想不到的位置。如果精心设计我们的字符串,我们甚至可以控制ret指令跳转到的内存地址。
¶ 实验准备
首先连接ICSserver。
与上次bomblab不同的是,这次你会在自己的用户目录下发现一个target.tar文件。
我们在终端下使用tar -xvf命令打开这个tar文件:
linux$ tar -xvf target.tar
targetxx/lib/
targetxx/lib/printf.so
targetxx/README.txt
targetxx/ctarget
targetxx/rtarget
targetxx/farm.c
targetxx/cookie.txt
targetxx/hex2raw
targetxx/autograder.py
targetxx/Makefile
现在用户目录下就会有一个targetxx目录(target+每个同学独有的ID),进入到targetxx目录中,可以使用ls命令列出所有内容:
linux$ cd targetxx
linux$ ls
README.txt autograder.py cookie.txt ctarget farm.c hex2raw lib Makefile rtarget
目录下有这些文件,如下表所示:
| 文件名 | 简介 |
|---|---|
README.txt |
描述目录下各个文件的内容 |
ctarget |
易受到代码注入攻击(Code Injection Attacks)的可执行程序 |
rtarget |
易受到返回导向编程攻击(Return-oriented Programming Attacks)的可执行程序 |
cookie.txt |
8位十六进制代码,每位同学的不同,在有些攻击中会用到。 |
farm.c |
gadget farm的源代码,你将使用这些gadget farm来完成返回导向编程攻击。(后续会介绍gadget farm) |
hex2raw |
生成攻击字符串的文件(使用方法见附录A) |
autograder.py |
计算分数的python脚本 |
lib/ |
lib/目录是ctarget和rtarget需要的依赖,你不需要修改其中的内容 |
Makefile |
可以帮助你生成最终提交的文件xxx-ics-handin.zip |
¶ Target程序
¶ target程序简介
总的来说,你的任务是攻击两个程序,ctarget和rtarget, 这两个程序都从标准输入读取字符串,所使用的函数getbuf定义如下:
unsigned getbuf()
{
char buf[BUFFER_SIZE];
Gets(buf);
return 1;
}
函数Gets类似于标准库函数中的gets函数,它从标准输入读取一个字符串(以"\n"或文件结束符结束),并将其存储(连同一个空终止符)在指定的目的地。在此示例中,目的地是名为buf的数组,其大小由编译时常量BUFFER_SIZE定义。
函数Gets()和gets()没有约束输入字符串的长度,它们只是简单地复制字节序列,因此如果输入的字符串太长可能会超出原本分配的存储空间。例如,在这个程序中就可能会超出buf数组的长度,造成缓冲区溢出(buffer overflow)。
正常情况下,如果用户输入(即由getbuf读取)的字符串长度适中,getbuf将返回1,如下面的执行示例所示:
linux$ ./ctarget
Cookie: 0x6f9798cf
Type string:123123
No exploit. Getbuf returned 0x1
Normal return
如上,输入了字符串123123,运行结果是Normal return,可以正常执行。
如果用户输入的字符串过长,通常会出现段错误(segmentation fault),这是因为你输入的字符串覆盖了栈中的有效信息。如下:
linux$ ./ctarget
Cookie: 0x59b997fa
Type string:This is not a very interesting string, but it has the property ...
Ouch!: You caused a segmentation fault!
Better luck next time
FAIL
程序rtarget与ctarget的运行过程基本相同。
¶ 怎么攻击target?
正如错误信息所示,缓冲区溢出通常会导致程序状态被破坏或内存访问错误。你的任务是构造一个特殊的"字符串",使得ctarget和rtarget不是简单的发生一个segmentation fault,而是按照我们提供一种"特殊字符串"的指引让ctarget和rtarget执行一些特定的操作。这些用于攻击的"特殊字符串"被称为exploit字符串。
ctarget和rtarget都提供了几个不同的命令行参数:
-h: 打印帮助信息-i FILE: 从文件中输入,而不是从标准输入中输入
由于ctarget和rtarget这两个程序接收的是字符串输入,但是你在攻击中需要使用的“exploit字符串”的有些字符可能不是ASCII字符集中对应的可打印的字符。例如,一个字节的值是0x31,在ASCII中对应字符’1’,这是可以直接从键盘输入的;但是如果一个字节的值是0x00,我们通常没有直接对应的字符可以输入。
为了解决这个问题,我们提供了hex2raw工具。即使你需要一些无法输入的字符,hex2raw也可以生成对应字节的字符串,我们称为原始字符串(raw string),有关使用hex2raw的详细信息,以及如何利用原始字符串进行gdb调试,请阅读附录A(本文末尾)。
虽然说原始字符串可以作为ctarget和rtarget的直接输入,但是原始字符串的文件打开时通常是一堆乱码,不适合阅读和分析,所以hex2raw工具可以让你直接得到其每个字节的十六进制表示,因此你可以专注于构造一个字符串的十六进制表示,需要原始字符串时只需要使用hex2raw转换一下即可。
攻击时要注意
你在进行攻击时利用的exploit字符串在任何中间位置都不能包含字节值
0x0a,因为这是换行(‘\n’)的ASCII码。当Gets遇到这个字节时,它会将其作为字符串的终止符。你可以使用一个或多个用空格分隔的两位十六进制值作为
hex2raw的输入。因此,如果要创建一个十六进制值为0的字节,则需要将其写成00。例如要构造0xdeadbeef这个值,你应该向hex2raw输入"ef be ad de"(注意小端模式下的字节顺序需要反过来)。
如果你完成了一个十六进制表示的字符串的文件,例如文件phase1.txt,应该如下所示:
/* phase1.txt */
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
/* some comments */
11 22 33 11 22 33 00 00
...
...
那么如何测试你的攻击是否成功呢?假设你在进行第一阶段实验的攻击时,你可以使用hex2raw生成phase1.txt的原始字符串文件raw1.txt,然后用raw1.txt作为ctarget的输入。
具体的linux命令如下,下面给出了一个典型的运行结果(如果你的phase1.txt是正确的):
linux$ ./hex2raw < phase1.txt > raw1.txt
linux$ ./ctarget < raw1.txt
Cookie: 0x59b997fa
Type string:Touch1!: You called touch1()
Valid solution for level 1 with target ctarget
PASS
上面代码中的
<和>是linux中的I/O重定向符号,详见input-output-redirection-in-linux
./hex2raw < phase1.txt > raw1.txt的意思是将phase1.txt的内容作为输入重定向到./hex2raw中,然后将./hex2raw的输出重定向到raw1.txt文件中。
./ctarget < raw1.txt的意思是将raw1.txt的内容作为输入重定向到./ctarget中。
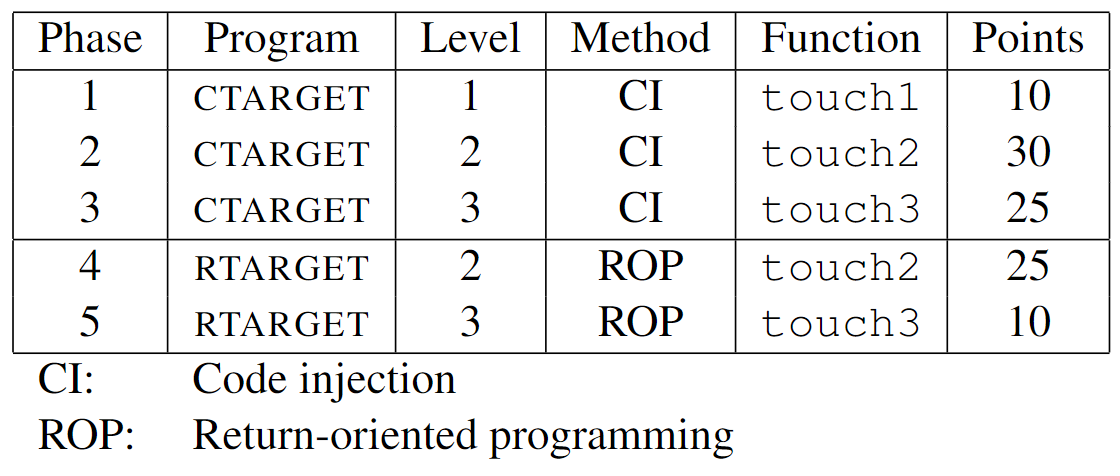
上图总结了实验的五个阶段(phase)。可以看出,前三个阶段涉及对ctarget的代码注入(Code Injection, CI)攻击,后两个阶段涉及对rtarget的返回导向编程(Return-oriented Programming, ROP)攻击。
¶ 实验流程
本实验设计了5个阶段(phase 1 - phase 5),前三个阶段你需要攻击ctarget,后两个阶段你需要攻击rtarget,ctarget和rtarget都以原始字符串作为输入,但是根据上文我们得知有些原始字符串是不容易直接输入的,为此我们需要先写出原始字符串对应的十六进制表示,例如上文中的phase1.txt,然后通过hex2raw程序来生成phase1.txt对应的原始字符串文件raw1.txt。
一个比较推荐的实验流程如下(以阶段1为例):
- 首先,你需要在目录下新建一个文件
phase1.txt(利用vscode左侧目录新建文件或者在终端使用touch phase1.txt都可以)。这个文件用来作为我们输入字符串的十六进制表示 - 然后,你可以尝试在
phase1.txt中输入你的字符串的十六进制表示 - 接下来,你可以使用
hex2raw生成原始字符串文件,例如下面的命令生成了一个原始字符串文件raw1.txt
linux$ ./hex2raw < phase1.txt > raw1.txt
- 然后你可以使用
gdb来调试
linux$ gdb ctarget
- 在gdb调试时可以通过
run < raw1.txt运行,进行调试:
(gdb) run < raw1.txt
- 如何判断是否攻击成功呢?你可以将你生成的原始字符串文件作为
./ctarget的输入,命令如下:
linux$ ./ctarget < raw1.txt
Cookie: 0x59b997fa
Type string:Touch1!: You called touch1()
Valid solution for level 1 with target ctarget
PASS
如果得到类似的输出,那恭喜你,攻击成功!
你修改
phase1.txt后需要要及时通过第2步的命令更新raw1.txt,否则运行./ctarget < raw1.txt得到的可能是旧的结果。
- 最后可以使用
autograder.py测试你的得分。
linux$ python3 autograder.py
phase1 Score: 10 / 10
phase2 Score: 0 / 30
phase3 Score: 0 / 25
phase4 Score: 0 / 25
phase5 Score: 0 / 10
Total Score: 10 / 100
autograder.py的工作流程是读取phase1~5.txt文件,并自动转化为原始字符串输入到对应的ctargetrtarget中,所以注意如果你的文件名并不是phase1~5.txt,那运行autograder.py是没有分数的。
¶ 第一部分:代码注入攻击(Code Injection Attacks)
在前三个阶段(phase),你将利用字符串攻击ctarget。该程序的堆栈位置在每次运行时都是不变的,因此堆栈上的数据可被视为可执行代码。这些特性使程序很容易受到攻击,因为你可以在你的攻击字符串中加入汇编指令的机器码。
¶ 阶段 1 (LEVEL 1)
在第1阶段,你不需要注入可执行代码。你的exploit字符串将重定向程序,使其执行现有程序touch1。
函数getbuf 在 ctarget 中被函数test调用,其C语言代码如下:
void test()
{
int val;
val = getbuf();
printf("No exploit. Getbuf returned 0x%x\n", val);
}
当 getbuf 执行其返回语句(getbuf 的第 5 行)时,程序通常会在函数test中(该函数的第5行)继续执行。我们希望改变这种执行顺序。在文件ctarget中,有一个函数touch1的代码,其C语言表示如下:
void touch1()
{
vlevel = 1;/* Part of validation protocol */
printf("Touch1!You called touch1()\n");
validate(1);
exit(0);
}
在这个任务中,你需要构造一个特殊的输入字符串—“exploit字符串”,使得ctarget程序中的getbuf函数在执行其返回语句的时候不按照常规流程返回到test函数,而是跳转到touch1函数并执行其代码。这意味着你需要利用精心构造的exploit输入覆盖getbuf函数的返回地址,使之指向touch1函数的起始地址。
请注意,你所构造的exploit字符串可能会对调用栈上getbuf函数之外的部分造成影响。但是,由于touch1函数的执行将导致程序立即退出,因此你不需要担心对栈的其他部分造成破坏。你的主要目标是确保能够成功调用touch1函数。
¶ 建议
- 使用
objdump -d ctarget命令获取ctarget程序的反汇编代码。- 在反汇编代码中可以确定
touch1函数的起始地址,并尝试使用这个地址覆盖getbuf的返回地址。注意在构造exploit字符串时,地址应该以字节形式表示,并且要注意字节的顺序(即小端顺序,使得低地址的字节在前)。- 利用
gdb调试工具来检查getbuf函数执行的最后几条指令是否按照你的预期工作。buf数组在getbuf函数的堆栈帧中的具体位置取决于BUFFER_SIZE的大小以及gcc的堆栈分配策略。你需要查看ctarget的反汇编代码来确定buf数组的准确位置,以便决定在exploit字符串的什么位置插入touch1的地址。
¶ 提示
你可能需要通过攻击实现一个如下图所示的栈结构:
在上图中你需要把左边正常栈中的ret addr部分覆盖为touch1函数的入口地址。

¶ 阶段 2 (LEVEL 2)
在第2阶段中,你的任务是将一小段可执行代码注入到exploit字符串中。这段代码将作为exploit字符串的一部分,并在攻击时执行touch2,touch2的参数是你的cookie.txt文件中的值。
在ctarget 文件中,有一个函数 touch2,其 C语言源代码如下:
void touch2(unsigned val)
{
vlevel = 2; /* Part of validation protocol */
if (val == cookie) {
printf("Touch2!: You called touch2(0x%.8x)\n", val);
validate(2);
} else {
printf("Misfire: You called touch2(0x%.8x)\n", val);
fail(2);
}
exit(0);
}
你的任务是让在ctarget程序中的getbuf函数在返回时不按照常规流程返回到test函数,而是跳转到touch2函数并执行其代码。关键在于,在运行touch2的时候,你需要将“cookie”值作为参数传递给它。这个“cookie”值对于每位同学都是唯一的,touch2函数需要接收到正确的“cookie”值才能攻击成功。
¶ 建议
- 你将会注入一段可执行代码到内存中,因此你需要获得这段可执行代码的地址,从而使得
getbuf代码末尾的ret指令可以跳转到你注入的可执行代码的地址。- 根据
x86-64的调用约定,函数的第一个参数是通过%rdi寄存器传递的。因此,你注入的可执行代码应该包括设置%rdi寄存器为你的“cookie”值的指令。- 你的注入代码应该以一个
ret指令结束,这将使得程序可以跳转到touch2函数的开始。- 本次实验禁止在你攻击的exploit代码中使用
jmp或call指令(理由是构建这些指令的目的地址的编码可能会比较复杂),所有跳转都要使用ret指令实现。- 如何知道汇编代码对应的字节序列?你可以参考附录B,了解如何使用
gcc工具来将汇编代码转换成字节表示形式。
¶ 提示
你可能需要通过攻击实现一个如下图所示的栈结构:
在上图中,注意攻击后的栈,你需要自己注入一段可以执行的代码(Your Injection Code)这段代码以ret结尾,然后你需要尝试将正常栈中的ret addr部分覆盖为你注入代码(Your Injection Code)的地址,同时你需要在栈的最后加入touch2函数的入口地址,保证你的注入代码的ret指令会跳转到touch2。你在
gdb调试时,当运行到你自己注入的代码时,可能会出现gdb找不到调用栈的情况,在gdb中表现为??,这属于正常现象,你可以根据指令的地址以及寄存器的值来判断你注入的代码是否正常运行。在这里当然还有很多其他做法,例如你可以尝试使用
push指令,将某个地址压入栈中。

¶ 阶段 3 (LEVEL 3)
第3个阶段也是代码注入攻击,与阶段2类似,攻击时需要使程序执行touch3,但是touch3需要一个字符串作为其参数。
在ctarget文件中,有函数hexmatch和touch3的代码,其C语言源代码如下:
/* Compare string to hex represention of unsigned value */
int hexmatch(unsigned val, char *sval)
{
char cbuf[110];
/* Make position of check string unpredictable */
char *s = cbuf + random() % 100;
sprintf(s, "%.8x", val);
return strncmp(sval, s, 9) == 0;
}
void touch3(char *sval)
{
vlevel = 3; /* Part of validation protocol */
if (hexmatch(cookie, sval)) {
printf("Touch3!: You called touch3(\"%s\")\n", sval);
validate(3);
} else {
printf("Misfire: You called touch3(\"%s\")\n", sval);
fail(3);
}
exit(0);
}
你的任务是让ctarget程序中的getbuf函数在返回时不按照常规流程返回到test函数,而是跳转到touch3函数并执行其代码。关键在于,在运行touch3的时候,你需要将以字符串形式表示的“cookie”值作为参数传递给它。touch3函数需要接收到正确的“cookie”值的字符串才能攻击成功。
¶ 建议
- 你在攻击时利用的exploit字符串中需要包含
cookie的字符串表示形式。该字符串应包含8个十六进制数字字符(从最高有效位到最低有效位),不含前导 “0x”。- 在
C语言中,字符串被表示为字符的序列,以NULL字节(即字节值为0)结尾。因此,在你的exploit字符串中,cookie的字符串表示形式后面应该跟着一个NULL字节。- 可以通过在
Linux终端中运行man ascii命令来查看字符对应的ASCII字节值。这将帮助你确保你的cookie字符串中的每个字符都被正确地转换成相应的字节值。- 你注入的代码需要将
%rdi寄存器设置为cookie字符串的地址。- 当调用
hexmatch或strncmp两个函数时,这些函数会将一些数据压入栈,这可能会覆盖getbuf使用的缓冲区。因此,如果你要将cookie字符串存放在栈上,你需要谨慎一些,以避免它被意外覆盖。
¶ 提示
与
phase2不同的是,这次你需要在内存中写一个字符串,为了防止字符串被覆盖,你可以考虑将你的字符串写在test函数的栈空间中。
¶ 第二部分:返回导向编程(Return-oriented Programming)
对rtarget程序进行攻击比ctarget更加复杂,因为rtarget采用了两种技术来增加安全性,这些技术使得传统的代码注入攻击更难实施:
- 栈随机化:
rtarget使用栈随机化技术,这意味着每次程序运行时,栈的位置都会有所不同。由于栈的位置不固定,我们无法预先知道注入代码的确切地址,这大大增加了直接在栈上注入并执行代码的难度。 - 栈执行保护: 程序还将栈区域标记为不可执行,即使攻击者成功地将代码注入到栈上,也无法将程序计数器(PC)指向栈上的代码并执行,因为操作系统会阻止从不可执行区域执行代码。
遗憾地是,聪明的黑客们已经设计出了一些策略,通过执行现有代码而不是注入新代码实现攻击。其中最普遍的形式被称为返回导向编程(ROP)。ROP的策略是在现有程序中找出由一条或多条指令组成的字节序列,这些指令后跟指令ret。这样的程序段被称为gadget。
下图说明了如何设置堆栈来执行n个gadget的序列。在该图中,栈上有一些gadget地址,这些地址指向各个Gadget。每个Gadget由一系列指令的字节组成,最后一个字节为0xc3,是ret指令的字节编码。当栈是这样的时候,如果程序此时执行了一个ret指令,那程序会立即执行栈顶也就是Gadget1的代码,Gadget1末尾的ret指令又会使程序执行Gadget2的代码,依次类推,程序会执行一连串的Gadget,每个Gadget末尾的ret指令都会使程序跳转到下一个Gadget的起点。
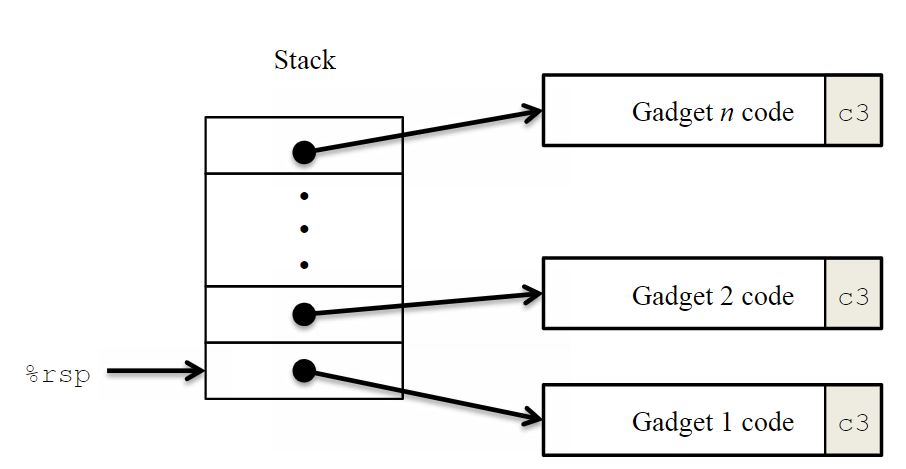
在返回导向编程(ROP)中,我们的gadget会经过编译器编译生成汇编代码,我们可以利用这些汇编指令进行攻击,特别是函数末尾部分的一些汇编指令(因为函数最后一般会有ret)。实际上,可能会有一些很好用的gadget,但它们数量有限,不足以实现许多重要的操作。例如,编译后的函数中很少会以popq %rdi作为ret之前的最后一条指令。幸运的是,对于像x86-64这样的面向字节的指令集,我们常常可以通过提取指令的字节序列中的某些部分来构造所需的gadget。这意味着,即使没有直接可用的gadget,我们也可以通过拆分现有的指令片段来创造出新的gadget。
例如, rtarget的C语言源码中有一个函数是这样定义的:
void setval_210(unsigned *p)
{
*p = 3347663060U;
}
乍一看,这个函数似乎没有办法用于我们的攻击。但是我们将这个函数进行反汇编之后,就得到了一个有趣的字节序列:
0000000000400f15 <setval_210>:
400f15: c7 07 d4 48 89 c7 movl $0xc78948d4,(%rdi)
400f1b: c3 retq
注意movl $0xc78948d4,(%rdi)的字节序列的后半段48 89 c7,对应指令 movq %rax, %rdi的字节序列(一些常用的movq指令编码见下图A)。该序列之后是编码ret指令的字节值c3。函数setval_210从地址0x400f15开始,指令 movq %rax, %rdi的序列从函数的第4个字节开始。因此,这段代码包含一个起始地址为0x400f18的gadget,它可以实现把寄存器%rax中的64位值传递给寄存器%rdi。
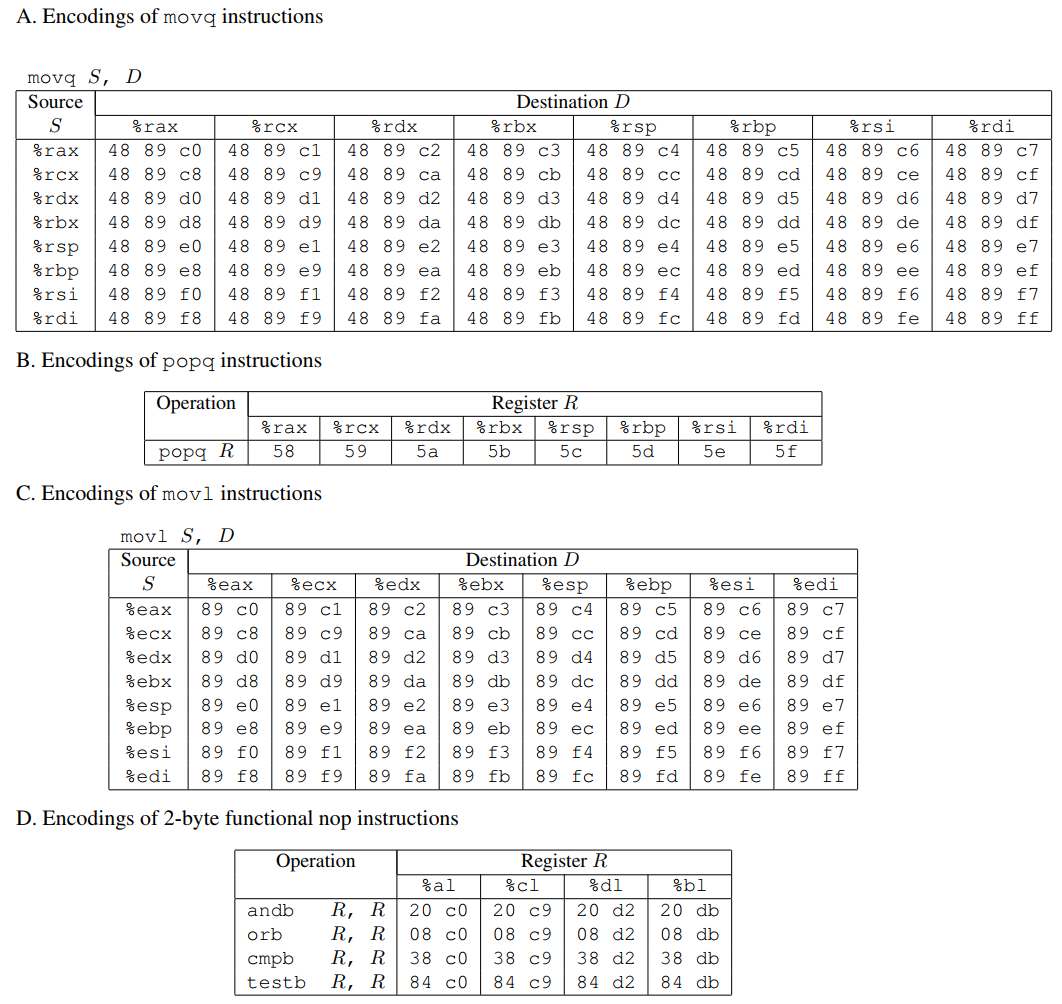
rtarget代码中包含许多类似于上图中setval_210的函数,这些函数位于名为gadget farm的区域中。你的任务是在gadget farm中找到对你有用的gadget,并利用这些gadget进行两次攻击,这两次攻击与第2和第3个phase基本相同。
注意:gadget farm是函数start_farm和end_farm之间的部分,不要且没必要试图从rtarget程序代码的其他部分构建gadget。
¶ 阶段 4 (LEVEL 2)
在第4阶段,你将重复第2阶段的攻击,但需要在rtarget程序中利用到gadget farm中的gadget。你可以使用由以下指令类型组成的gadget进行攻击,并且只允许使用 x86-64的前8个寄存器(%rax-%rdi)。
movq:其代码如上图A所示。popq:其代码如上图B所示。ret:该指令由单字节0xc3编码。nop:该指令(是 "无操作"的简称)由0x90单字节编码。它的唯一作用是使程序计数器加1。
¶ 建议
- 你可以在
rtarget反汇编代码中的函数start_farm和mid_farm之间找到所有所需的所有gadget。- 只需两个
gadget就能完成这次攻击。gadget使用popq指令时,会从堆栈中弹出数据。
¶ 提示
现在栈中的代码不可执行,同时存在栈随机化,所以只能用程序中现有的代码去组合一些代码去做操作,这里我们利用的是程序中的一些
gadget函数的一些字节序列。
¶ 阶段 5 (LEVEL 3)
注意:本阶段难度较大
终于你来到了最后一个阶段,在进行第 5 阶段之前,请先静下心来想一想你迄今为止已经完成了哪些工作。在第 2 和第 3 阶段,你让一个程序执行了你自己设计的机器代码。假如ctarget 是一台网络服务器,你或许已经能够将自己的代码注入到一台远程机器中了。在第4阶段,你绕过了现代操作系统用来阻止缓冲区溢出攻击的两个主要机制。虽然你没有注入自己的代码,但你能够注入一种通过拼接现有代码序列来运行的程序。
第5阶段要求对rtarget进行ROP攻击,用指向用字符串表示的cookie的指针调用函数touch3。此外,第5阶段只占10分,但是并不代表这次攻击是最容易完成的。
要解决第5阶段的问题,可以在rtarget 中由函数start_farm 和end_farm 划分的代码区域中使用gadget。除了第4阶段使用的gadget外,这个扩展的farm还包括不同movl指令的编码,如上面的指令对应字节序列的图C所示。这一部分的字节序列还包含 2 字节指令,这些指令的功能是nops, 即不改变任何寄存器或内存值。在上面指令对应字节序列的图D中,图D中包括andb %al,%al等指令,它们对某些寄存器的低阶字节进行操作,但不改变寄存器的值。
提示:除了图A-D的指令外,你还可以使用
gadget farm中存在的其他指令。
¶ 建议
- 你可能需要复习一下
movl指令对寄存器高位4个字节的影响,详见课本的3.4.2。- 官方题解需要8个
gadget(当然不唯一)。
Good luck and have fun!
¶ 评分方法与代码提交
¶ 评分方法
各个phase占比如下:
phase1:10分
phase2:30分
phase3:25分
phase4:25分
phase5:10分
为了方便评分,这里要求大家将解题过程所使用的十六进制数字形式的文件分别命名为phase1~5.txt,例如phase3的十六进制数字形式的答案你需要放在phase3.txt文件中,正确命名后,大家可以使用实验目录下的autograder.py文件计算自己的得分,一个典型的运行结果如下:
linux$ python3 autograder.py
phase1 Score: 10 / 10
phase2 Score: 30 / 30
phase3 Score: 25 / 25
phase4 Score: 25 / 25
phase5 Score: 0 / 10
Total Score: 90 / 100
¶ 迟交
在超过原定的截止时间后,我们仍然接受同学的提交。此时,在lab中能获得的最高分数将随着迟交天数的增加而减少,具体服从以下给分策略:
超时7天(含7天)以内时,每天扣除3%的分数
超时7~14天(含14天)时,每天扣除4%的分数
超时14天以上时,每天扣除7%的分数,直至扣完
以上策略中超时不足一天的,均按一天计,自ddl时间开始计算。届时在线学习平台将开放迟交通道。
评分样例:如某同学小H在lab中取得95分,但晚交3天,那么他的最终分数就为95*(1-3*3%)=86.45分。同样的分数在晚交8天时,最终分数则为95*(1-7*3%-1*4%)=71.25分。
¶ 代码提交
大家在自己目录下运行make handin命令,会生成一个学号-ics-handin.zip文件,并且还会检测当前目录下是否存在phasex.txt。
例如一位同学小L完成了phase1~phase4的攻击,同时小L没有写phase5.txt,一个典型的运行结果如下:
linux$ make handin
Warning: phase5.txt does not exist and will be skipped
packed to xxxxx-ics-handin.zip
Warning: phase5.txt does not exist and will be skipped提示小L目录中没有phase5.txt,于是跳过了phase5.txt,完成打包。
大家将这个学号-ics-handin.zip文件下载下来,并重命名为学号-ics-lab3-handin.zip,在在线学习平台上的作业模块中,将该文件作为附件提交即可。
¶ 附录A: 使用 hex2raw
hex2raw输入十六进制格式的字节序列。在这种格式中,每个字节值由两个十六进制数字表示。例如,字符串 "012345 "可以十六进制格式输入为 “30 31 32 33 34 35 00”。

传递给hex2raw的十六进制字节应该用空格(空白或换行)分隔。建议你在编写时用换行分隔exploit字符串的不同部分。 hex2raw支持与C语言类似的多行注释,因此你可以标记exploit字符串的各个部分。例如
48 C7 C1 F0 11 40 00 /* MOV$0X40011F0 ,%RCX */
确保在注释字符串(“/"、 "/”)的起始和结束位置都留有空格,以便注释被正确地忽略。
如果你在文件phase1.txt中写了十六进制形式的字节序列,有几种不同的方法可以将这些字节序列对应的原始字符串输入到ctarget或 rtarget :
- 你可以通过管道,让十六进制字节序列输入到
hex2raw,再通过管道将hex2raw的输出原始字符串输入到ctarget。
linux$ cat phase1.txt | ./hex2raw | ./ctarget
- 你可以通过使用
I/O重定向,将phase1.txt输入hex2raw,再将原始字符串(raw string)存储在文件raw1.txt中:
linux$ ./hex2raw < phase1.txt > raw1.txt
linux$ ./ctarget < raw1.txt
- 你同样可以先将原始字符串(raw string)存入文件
raw1.txt中,并使用ctarget或rtarget的-i参数读取文件内容作为输入:
linux$ ./hex2raw < phase1.txt > raw1.txt
linux$ ./ctarget -i raw1.txt
¶ GDB调试
在gdb中调试时可以使用这种方法。
例如我想调试ctarget程序,在命令行输入gdb ctarget进入gdb调试。
linux$ gdb ctarget
GNU gdb (Ubuntu 12.1-0ubuntu1~22.04) 12.1
Copyright (C) 2022 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ctarget...
(gdb)
例如可以先在getbuf打入断点:
(gdb) b getbuf
Breakpoint 1 at 0x4017a8: file buf.c, line 12.
(gdb)
运行时,第一种方法是可以使用run -i raw1.txt
(gdb) run -i raw1.txt
Starting program: /home/ygli/target1/ctarget -i raw1.txt
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Cookie: 0x59b997fa
Breakpoint 1, getbuf () at buf.c:12
12 buf.c: No such file or directory.
(gdb)
gdb中的12 buf.c: No such file or directory.提示我们目录下并没有源文件的源码,这里并没有给出buf.c的源文件,但是并不影响我们的实验。
第二种方法是可以使用run < raw1.txt,将原始字符串作为输入。
(gdb) run < raw1.txt
Starting program: /home/ygli/target1/ctarget < raw1.txt
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Cookie: 0x59b997fa
Breakpoint 1, getbuf () at buf.c:12
12 buf.c: No such file or directory.
¶ 附录B: 生成汇编指令的机器码
使用gcc作为汇编程序,objdump作为反汇编程序,可以方便地得到汇编指令的机器码(使用16进制表示)。例如,假设你编写的文件example.s包含以下汇编代码:
# Example of hand-generated assembly code
pushq $0xabcdef # Push value onto stack
addq $17, %rax # Add 17 to %rax
movl %eax, %edx # Copy lower 32 bits to %edx
汇编代码可以包含指令和数据。 #字符右边的内容都是注释。
现在你可以汇编和反汇编该文件:
linux$ gcc -c example.s
linux$ objdump -d example.o > example.d
生成的文件 example.d包含以下内容:
example.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <.text>:
0: 68 ef cd ab 00 pushq $0xabcdef
5: 48 83 c0 11 add $0x11,%rax
9: 89 c2 mov %eax,%edx
底部各行显示的是由汇编语言指令生成的机器码。每行左侧的十六进制数字表示指令的起始地址(从 0 开始)。: 字符后的十六进制数字表示汇编指令的机器码。因此,我们可以看到pushq $0xabcdef指令的十六进制机器码为68 ef cd ab 00。
从该文件中,你可以获得代码的十六进制格式的序列:
68 EF CD AB 00 48 83 C0 11 89 C2
然后,这个字符串可以通过hex2raw生成目标程序的输入字符串。通过修改 example.d,可以省略无关值,同时可以添加注释以提高可读性,如下,这是加上注释的版本,这也是一种有效的输入,可以在发送给目标程序之前通过 hex2raw生成原始字符串作为输入。
68 EF CD AB 00 /* PUSQ $0XABCEF */
48 83 C0 11 /* Add $0X11 ,%RAX */
89 C2 /* MOV %EAX ,%EDX */